Nomina si nescis, perit et cognitio rerum.
Carl von Linné
(If you know not the names of things, the knowledge of things themselves perishes.)
Active inference framework
Notation notes
- Time sequences: Time sequences are indexed with the subscript \(k\) where the subscript \(0\) represents the present time. Negative numbers represent the past and positive numbers represent the future. The time intervals between the time samples are not assumed to be equidistant.
- Shorthand: A random variable without a subscript, e.g., \(s\), is a shorthand for a time sequence of the random variable where applicable. When referring to a random variable at a specific time sample, a single subscript is used, e.g., \(s_0\).
- Tilde: A tilde over a probability distribution, like \(\tilde p(s)\) or \(\tilde p(o)\), means that the distribution is a normative distribution, rather than a neutral prediction. It defines what states the system ought to be in rather than which states it is in.
- Structure: While the goal has been to order the definitions from atomary and primitive terms to composite terms, this has not always succeeded. Some scrolling both up and down may be needed to fully understand a term.
System: An arrangement of interacting elements that together realize functions. Examples include information systems, biological organisms, ant hills, medical devices, and space stations.
Open system: A system that has external interactions. Such interactions can take the form of information, energy, or material transfers into or out of the system boundary.
Distribution, probability distribution: A mathematical function or table that describes the likelihood of all possible outcomes for a random variable, discrete or continuous. Quantified with a probability density function (continuous random variables) or a probability mass function (discrete random variables).
State vector: An ordered array of state variables that mathematically defines a single point within a state space \(\Omega\). Within active inference, a state vector represents either the physical state (\(\eta\)) of the controlled system or an information state (\(s, o, a\)) within a controller layer.
State variable: A component of a state vector. State variables can be categorical or continuous.
State: The current value of the state vector.
State space, \(\Omega\): The bounded, multi-dimensional mathematical space (or manifold) comprising all permissible state vectors for a given system or controller layer. Its dimensions are spanned by the domains of its constituent state variables. If a state vector consists of \(N\) distinct state variables, where each variable \(i\) belongs to its own domain \(\mathcal{X}_i\) (which can be continuous, such as \(\mathbb{R}\), or categorical), the complete state space is the Cartesian product of these domains:
$$\Omega = \mathcal{X}_1 \times \mathcal{X}_2 \times \dots \times \mathcal{X}_N = \prod_{i=1}^N \mathcal{X}_i$$
Any specific state vector, e.g., a representational state \(s\) or a physical state \(\eta\), is a single point within this coordinate system, uniquely defined by the simultaneous values of its constituent state variables:
$$s = \begin{bmatrix} s^{(1)} \\ s^{(2)} \\ \vdots \\ s^{(N)} \end{bmatrix} \in \Omega_s$$
In hierarchical architectures, different controller layers \(\mathcal{C}^{(i)}\) generally operate over distinct state spaces spanned by different state variables, where higher levels span more abstract, compressed, or macro-level state spaces than the levels beneath them.
Physical state, \(\eta\): The mathematical representation of the thermodynamic, chemical, or mechanical arrangement of a physical system’s matter and energy. It is a “God’s eye” vector that can only be estimated through observations and is therefore never fully accessible for an observer.
The physical state of a passive (uncontrolled) physical system evolves according to the equation:
$$d\eta = f(\eta)dt + d\omega_\eta$$
where \(\omega_\eta\) represents random perturbations of the state.
Examples of state variables of the physical state include the physical temperature of the human body, the ATP concentration in a cell, and the momentum of a vehicle.
Controlled system state, \(\eta, s\): The state of either a controlled physical system such as a body or the state of a controller layer if controlled by a higher controller layer.
Generative process: The dynamics of an open system.
Controlled system: A system that is kept within a limited, defined set of states by the actions of a controller. Examples of controlled physical systems include individual cells, organisms, tissue and organs, the whole human body, and the habitat of certain organisms capable of modifying their habitat.
A controller controlled by a higher controller level in a hierarchical controller.
Control: The act of keeping a controlled system within a limited, defined set of states.
Predictive control: Control with the use of a dynamic system model that is used to predict future controlled system states over a time horizon.
Active inference: A general form of predictive control consisting of planning and generation of action states to control a system to keep it on a viable manifold by minimizing a quantity called free energy. All control algorithms capable of sustaining NESS are subsets of active inference.
Non-equilibrium steady state (NESS): A physical state of an open system that is constantly kept out of equilibrium by external forces, such as energy, matter, or information flux. Unlike equilibrium, NESS features persistent currents (e.g., heat flow, particle transport), continuous entropy production, and is maintained through constant interaction with its environment.
Organism: A system maintaining NESS (as long as it is alive).
Controller layer, \(\mathcal{C}^{(i)}\): A system that gets information about the state of a controlled system via transducers and controls it via effectors so as to keep it within a limited, defined set of states, or so as to orchestrate otherwise purposeful system state transitions within the allowed set of states. In active inference the allowed set of states is defined by the controlled system’s viable manifold.
Controller, \(\mathcal{C}\): A hierarchy of controller layers.
- The lowest-level controller layer \(\mathcal{C}^{(1)}\) controls the physical states (\(\eta\)) of a physical controlled system.
- A higher-level controller layer \(\mathcal{C}^{(i)}\), \(i > 1\) controls the information state of the controller layer below it. For the higher-level controller layer, the lower-level controller layer is its controlled system.
Note on Implementation: The physical realization of a controller is often part of the system it controls (e.g., the human brain is part of the human body). When the controlled system is a lower-level controller layer, interactions occur entirely within the information domain. The “transducers” and “effectors” and effectors of higher-level controller layers are informational interfaces—specific computational mappings and synaptic projections forming the Markov blanket between hierarchical layers. They filter lower-level states into higher-level observations and translate higher-level actions into lower-level empirical setpoint distributions.
Reflexive controller layer: A controller layer that infers a recognition distribution \(q(s_0)\) and generates actions \(a\) based on an observation \(o_0\), using a normative generative model, minimizing variational free energy \(\mathcal{F}\).
Temporal controller layer: A controller layer that operates over the time sequence \(-N:K\):
- It infers its recognition distribution \(q(s_{-N:0}, \pi_{-N:-1})\) from observations \(o_{-N:0}\), using the predictive generative model (smoothing), minimizing retrospective free energy.
- It infers a waypoint distribution guiding future actions by generating alternative policies from its policy space \(\mathcal{U}\), using the predictive generative model, selecting a policy that minimizes expected free energy \(G(\pi)\).
Physical viable manifold, \(\mathcal{M}_\eta\): The physical state manifold \(\mathcal{M}_\eta\) defines the states wherein the system maintains its NESS (“remains alive”). It is defined by:
$$\mathcal{M}_\eta = \{ \eta \in \Omega_{\eta} : p(\eta) > \epsilon_{\eta} \}$$
Information state, \(s, o, a\): A state vector whose state variables (components) are random variables representing quantities of interest within the controller layer. The three types of information states in active inference are:
- Observation, \(o\)
- Action, \(a\)
- Representational state, \(s\)
Surprise, \(– \ln \tilde p(o)\): The negative logarithm of the probability as given by the generative model. The physical viable manifold of the controlled system can in a well calibrated controller be described as a viable manifold over observations:
$$\mathcal{M}_{\eta} \approx \{ o=g(\eta) \in \Omega_o : \tilde p(o) > \epsilon_o \}$$
Representational state, \(s, s_{[k_1:k_2]}\): A sequence of information states between time steps \(k_1\) and \(k_2\) within a controller layer. A representational state serves as an internal, mathematical proxy for the physical state \(\eta\) of the controlled system. Unlike a transient observation (\(o\)), which is a direct transformation of an observed state (\(\eta_o\)), a representational state is a potentially persistent inferential construct that “stands in for” the physical state (\(\eta\)) within the generative model.
Because generative models are typically hierarchical, representational states vary in their level of abstraction:
- Low-level representational states represent immediate, localized physical states (\(\eta\)) of the controlled system, e.g., \(\text{current joint angle}\).
- High-level representational states are compressed, complex, long-term configurations of lower-level states such as \(\text{social status}\) or \(\text{navigational goal}\).
Recognition distribution, \(q(s \mid \theta)\), \(q(s, \pi \mid \theta)\):
- q(s \mid \theta) is a variational distribution that acts as a tractable approximation of the intractable posterior distribution \(p(s \mid o)\) in a reflexive controller layer. It is the best estimate of the current representational state of the controller layer.
- q(s, \pi \mid \theta) is a variational distribution that acts as a tractable approximation of the intractable posterior distribution \(p(s, \pi \mid o) = p(s \mid \pi, o)p(\pi \mid o)\) in a temporal controller layer. \(s\) and \(\pi\) are past sequences of the respective random variables..
\(\theta\) represents the recognition distribution parameters such as the mean \(\mu\) and the precision \(\Pi\).
Observed state, \(\eta_o, s_o\): The subset of the physical state \(\eta_o\) that interacts with the controller layer’s transducers. The transducer transforms the observed state into an information state \(o\).
Within a hierarchy of controllers, the observed state of a controller layer \(\mathcal{C}^{(i)}\) is defined by the parameters of its recognition distribution \(\theta\) (e.g., the expected value or mode).
Observation, \(o, o_{[k_1:k_2]}\): A sequence of information states between time steps \(k_1\) and \(k_2\) within a controller layer representing observed states at different points in time.
Action state, \(\eta_a, s_a\): In a physical system, a continuous physical state (\(\eta_a\)) generated by an effector with the intention to perturb or maintain the system’s physical state against environmental dynamics. It is the physical realization of the lowest controller layer’s informational output \(a\), translated across the physical Markov blanket into a continuous force or flux:
$$d\eta = f(\eta, \eta_a)dt + d\omega_\eta$$
Within a hierarchy of controllers, the action state of a lower-level controller layer \(\mathcal{C}^{(i-1)}\) from the perspective of a higher-level controller layer \(\mathcal{C}^{(i)}\) is an information state \(s_a^{(i-1)}\). This state maps directly from the higher-level information action \(a^{(i)}\)—which is generated step-by-step as the higher-level controller layer unfolds its realized policy \(\pi^{*(i)}\)—across the computational Markov blanket to form the empirical setpoint distribution \(\tilde p(s^{(i-1)})\) of the lower-level controller layer.
Action, \(a\): A continous information state that drives an action state in the controlled system via an effector. The action state is a function of the action:
$$\eta_a = h(a)$$
Markov blanket \(b\): The set of boundary states \(\eta_b = \{\eta_o, \eta_a\}\), or \(s_b^{(i-1)} = \{s_o^{(i-1)}, s_a^{(i-1)}\}\) if separating a controller layer at level \(i-1\) from a controller layer at level \(i\).
The Markov blanket mediates all information between the controller states and controlled system states.
Mathematically the Markov property implies that:
$$p(s, \eta | \eta_b) = p(s | \eta_b)p(\eta | \eta_b)$$
or, if the Markov blanket separates two controller layers in the hiearchy of controllers:
$$p(s^{(i)}, s^{(i-1)} \mid s_b^{(i-1)}) = p(s^{(i)} \mid s_b^{(i-1)})p(s^{(i-1)} \mid s_b^{(i-1)})$$
The universe consists of many nested systems, each with their own Markov blanket.
Agency model (\(\frac{\partial o}{\partial a}\)): The controller layer’s internal mapping that defines its capacity to alter the system state and therefore its observations (\(o\)) by emitting an action (\(a\)) to drive effectors across the Markov blanket. It serves as the mathematical gatekeeper determining whether a free energy gradient is resolved via action (when agency \(\neq 0\)) or forced into perception/acceptance (when agency \(= 0\)).
Observation model, \(p(o \mid s)\): The controller layer’s internal model of its own sensors. It maps representational states \(s\) to expected observations \(o\). It defines how the controller expects a given physical state represented by \(s\) to manifest as sensory data (transformed by transducers). Its fidelity can be characterized by its sensitivity (the probability of an observation correctly indicating the presence of a state) and specificity (the probability of an observation correctly indicating the absence of a state). These parameters determine the precision of the likelihood and dictate how much the recognition distribution \(q(s \mid \theta)\) will shift its parameters upon receiving a new observation.
The observation model changes only slowly through learning and can be assumed to be constant during e.g., waypoint inference.
Transition model, \(p(s_k \mid s_{k-1}, \pi_{k-1})\): The “physics engine” of the generative model. It dictates how the controller layer expects the representational state \(s_{k-1}\) to evolve into the next state \(s_k\) as a consequence of a decision \(\pi_{k-1}\).
Deontic model, \(\tilde p(\pi_{k-1} \mid s_{k-1})\): Dictates what decisions (and thus actions) are physically possible, historically habitual, or morally required (duties) when in state \(s_{k-1}\), before any consequences of those decisions are calculated.
Update rate, \(\kappa_a, \kappa_\theta\): The rate constants (with dimension \([\text{time}]^{-1}\)) that govern the velocity of free energy gradient descent. They act as the physiological gain translating computational prediction errors into parameter updates or physical forces.
- Perception update rate, \(\kappa_\theta\): Dictates the rate at which the recognition distribution parameters \(\theta\) are updated.
- Action update rate, \(\kappa_a\): Dictates the rate at which the action state \(a\) changes to drive effectors.Higher-level controller layers dynamically modulate the \(\kappa\) parameters of lower-level controllers to explicitly gate whether local free energy is minimized via perception, action, or both.
Setpoint distribution, \(\tilde p(s), \tilde p(o)\): A probability distribution over representational states or observations that defines the target regions the controller is biased to occupy (the viable manifold). Mathematically, it occupies the position of a Bayesian prior. Functionally, it fulfills two simultaneous roles depending on the gating of the update rates:
- Pragmatic target (Action): When the action update rate \(\kappa_a > 0\), the setpoint distribution drives counter-gradients to alter the physical state \(\eta\) via effectors.
- Epistemic bias (Perception): When action is structurally impossible or physiologically inhibited (\(\kappa_a = 0\)), the free energy gradient must be resolved internally. The setpoint distribution acts as a perceptual expectation, heavily biasing the updating of the recognition distribution \(q(s \mid \theta)\) via the perception update rate \(\kappa_\theta\).
The total setpoint distribution evaluated by the controller layer is the integrated product of two components:
- Structural setpoint distribution, \(\tilde p_{struct}(s)\): Hardcoded, phylogenetically endowed probability distribution with high probabilities allocated to preferred representational states on the viable manifold (e.g., a distribution with a sharp peak at the optimal human body temperature of 37°C).
- Empirical setpoint distribution, \(\tilde p_{emp}(s)\): Probability distribution dynamically generated by a higher-level controller layer and passed down across the computational Markov blanket to serve as an active boundary condition for a lower-level controller (e.g., a distribution with high precision assigned to \(s = \text{hand holding a cup}\)).
Setpoint state, \(\tilde s\): The mode of the setpoint distribution. While the controller layer mathematically minimizes the divergence between its recognition distribution and the entire setpoint distribution, the setpoint state serves as the functional target toward which the system’s counter-gradients (action) or perceptual biases (perception) are directed.
Note that for Gaussian distributions the mode equals the mean. Categorical distributions don’t have a well-defined mean but they have a mode (a most probable category).
Generative model, \(\tilde p(s_k, o_k), p(s, o, \pi)\): A controller layer’s internal model of the controlled system, mathematically relating representational states \(s\), observations \(o\), and policies \(\pi\). Active inference defines two types of generative models:
- Normative generative models
- Predictive generative models
Normative generative model, \(\tilde p(s_k, o_k)\): A joint probability distribution that defines the states the controller layer is biased to occupy and the observations expected for those states. It is the mathematical target for free energy minimization in both the present moment (variational free energy) and the projected future (expected free energy). It decomposes as:
$$\tilde p(s_k, o_k) = p(o_k \mid s_k) \tilde p(s_k)$$
Where:
- \(\tilde p(s_k, o_k)\): Joint target distribution over states and observations at time step \(k\).
- \(p(o_k \mid s_k)\): Observation model translating target states into expected observations.
- \(\tilde p(s_k)\): Setpoint distribution defining the target representational states.
- \(s_k, o_k\): Representational state and observation at time step \(k\).
While mathematically decomposable in multiple ways, only this configuration (observation model \(\times\) setpoint distribution) is implemented biologically.
Planning horizon: The future horizon over which a temporal controller layer plans its free energy minimization. It extends over the subscripts \([1 \ldots K]\), i.e., representational states \(s_1\) to \(s_K\). The planning horizon is defined by the upper index \(K\).
Retrospective horizon: The past horizon over which a temporal controller layer infers its recognition distribution \(q(s_{-N:0}, \pi_{-N:-1})\). The retrospective horizon is defined by the lower index \(N\).
Predictive generative model, \(p(s, o, \pi)\): A joint probability distribution used to simulate the evolution of states and observations over time. It is used by temporal controllers to generate predictive, counterfactual trajectories during waypoint inference and to infer past states during smoothing. It decomposes for one time step as:
$$p(s_k, o_k, \pi_{k-1} \mid s_{k-1}) = p(o_k \mid s_k) p(s_k \mid s_{k-1}, \pi_{k-1}) \tilde p(\pi_{k-1} \mid s_{k-1})$$
The predictive generative model for waypoint inference over the planning horizon is:
$$p(s_{0:K}, o_{1:K}, \pi_{0:K-1}) = p(s_0) \prod_{k=1}^K p(o_k \mid s_k) p(s_k \mid s_{k-1}, \pi_{k-1}) \tilde p(\pi_{k-1} \mid s_{k-1})$$
Where:
- \(s_{0:K}\): Sequence of representational states.
- \(o_{0:K}\): Sequence of observations.
- \(\pi_{0:K-1}\): Sequence of decisions; policy.
- \(p(s_0)\): Current representational state distribution, approximated by \(q(s_0 \mid \theta)\).
- \(\tilde p(s_k \mid s_{k-1}, \pi_{k-1})\): Transition model predicting state evolution based on the previous state and decision.
- \(p(\pi_{k-1} \mid s_{k-1})\): Deontic model defining decision priors.
The predictive generative model for perceptual inference over the retrospective horizon is:
$$p(s_{-N:0}, o_{-N:0}, \pi_{-N:-1}) = p(s_{-N}) \prod_{k=-N}^0 p(o_k \mid s_k) \prod_{k=-N}^{-1} p(s_{k+1} \mid s_{k}, \pi_{k}) \tilde p(\pi_{k} \mid s_{k})$$
with
$$p(s_{-N}) = \mathbb{E}_{q(s_{-N-1}, \pi_{-N-1})}[p(s_{-N} \mid s_{-N-1}, \pi_{-N-1})]$$
While mathematically decomposable in multiple ways, only this configuration (observation model \(\times\) transition model \(\times\) deontic model) is implemented biologically.
Waypoint state, \(s, s_{[1:K]}\): A sequence of intermediate, counterfactual representational states projected into the future to be visited on a trajectory toward a setpoint state. It represents the mode of a waypoint distribution (\(q(s_{[1:K]})\)) derived via waypoint inference.
Waypoint distribution, \(q(s_{[1:K]})\): A distribution of a waypoint states.
Waypoint inference: The process of deriving a waypoint distribution.
Generative model parameters, \(\phi\): The parameters (analogous to weights in deep learning) defining the generative model structure. Learning is defined as the optimization and updating of \(\phi\).
Computational viable manifold, \(\mathcal{M}_s\): The set of information states within which the controller layer’s internal model can successfully minimize free energy:
$$\mathcal{M}_s = \{ s \in \Omega_s : \mathcal F(s) < \epsilon_s \}$$
where \(\mathcal F(s)\) is free energy and \(\epsilon_s\) is the maximum threshold of prediction error before the control algorithm loses stability.
Decision, \(\pi_k\): A discrete control variable within a policy that acts as a parameter altering state transition probabilities within the transition model:
$$p(s_k \mid s_{k-1}, \pi_{k-1}) = B_{\pi_{k-1}} \Rightarrow q(s_k \mid \pi_{k-1}) = \sum_{s_{k-1}} p(s_k \mid s_{k-1}, \pi_{k-1}) q(s_{k-1})$$
Where:
- \(B_{\pi_{k-1}}\): Transition matrix representing the state transition probabilities from time sample \(k-1\) to \(k\) under decision \(\pi_{k-1}\).
- \(q(s_{k-1})\): Internal distribution over states at the previous time sample.
Note on standard literature: Decision is frequently denoted as “action” in traditional active inference literature, confusingly overloading the term with the physical/informational action state (\(a\)).
Policy, \(\pi\): A sequence of decisions \(\pi = (\pi_0, \pi_1, \dots, \pi_{K-1})\) evaluated within a bounded policy space (\(\mathcal U\)) during waypoint inference to guide the system toward its setpoint distribution.
Policy space, \(\mathcal U\): The bounded set of all possible sequences of decisions available to a controller layer.
Realized policy, \(\pi^*\): The single sequence of decisions selected from the inferred policy distribution \(q(\pi)\) for actual deployment by the controller layer. While waypoint inference evaluates a probability distribution over the policy space \(\mathcal{U}\), the controller layer must collapse this distribution into a single realized policy to orchestrate downstream actions. Under baseline conditions, the realized policy corresponds to the mode of \(q(\pi)\), but the selection mechanism may be modulated (e.g., via a temperature parameter) to realize sub-optimal or exploratory decision sequences.
Message: A transient data structure crossing the Markov blanket or moving temporally/laterally between states, containing free energy gradients or distribution parameters \(\theta\) (such as mean and precision).
Instantaneous free energy, \(\mathcal{F}_{inst}\): The real-time loss function computed by a reflexive controller layer to bound instantaneous surprise. It is minimized to drive immediate perception and reflex action. It is evaluated by comparing the current recognition distribution against the normative generative model (the target state):
$$\mathcal{F}_{inst} = D_{KL}[q(s_0 \mid \theta) \parallel \tilde p(s_0)] – \mathbb{E}_{q(s_0 \mid \theta)}[\ln p(o_0 \mid s_0)]$$
Retrospective free energy, \(\mathcal{F}_{retro}\): The sequential loss function computed by a temporal controller layer over a history of states. It is minimized exclusively through perception (filtering and smoothing) to accurately estimate the past and present based on empirical evidence. It is evaluated by comparing the internal sequence of beliefs against the predictive generative model (the physics engine):
$$\mathcal{F}_{retro} = \mathbb{E}_{q(s_{-N:0}, \pi_{-N:-1})}\left[ \ln q(s_{-N:0}, \pi_{-N:-1}) – \ln p(o_{-N:0}, s_{-N:0}, \pi_{-N:-1}) \right]$$
Expected free energy, \(G(\pi)\): The prospective loss function used during waypoint inference to evaluate a policy \(\pi\) over a future planning horizon. It balances pragmatic value (exploitation) with epistemic value (exploration) by comparing the simulated future generated by the predictive generative model against the goals defined by the normative generative model:
$$G(\pi) = \sum_{k=1}^K \mathbb{E}_{q(o_k, s_k \mid \pi_{0:k-1})} [ \ln q(s_k \mid \pi_{0:k-1}) – \ln \tilde p(s_k, o_k) ]$$
Smoothing, postdiction: The process of updating the recognition distribution over past representational states \(q(s_{-N:0})\) and decisions \(\pi_{-N:-1}\) given observations \(o_{-N:0}\) by minimizing retrospective free energy.
The table below summarizes the mapping between the terms above and conventional AIF terms.
| Term | AIF equivalent | Role |
| Controller | Agent; brain | The control system controlling the controlled system by minimizing free energy. |
| System; controlled system; allostatic system | Generative process | The physical system being controlled. |
| Physical state | External state | The state of the controlled system. |
| Controller layer state; information state | Hidden state; latent variable | The controller layer’s “guess” at the system state. |
| Viable manifold | Attracting set | The “safe” operating envelope of physical states. |
| Setpoint distribution | Prior; prior distribution; prior preferences; \(C\)-matrix | The setpoint or epistemic bias for the controller layer. |
| Decision | Action; control variable; \(u\) | Determines the probabilities for the state transitions in transition model calculations. |
| Waypoint inference | Discrete-time POMDP; sophisticated inference/planning; deep tree search; policy inference | Produces the trajectory of state distributions for reaching the setpoint distribution. |
| Deontic model | Prior over policies; habits; \(E\)-matrix | Prior preferences over policies such as habits or moral rules. |
| Normative generative model | Target joint distribution / Generative model (when applied to priors) | Defines target regions and expected sensory observations to act as the mathematical baseline for free energy minimization. |
| Predictive generative model | Empirical generative model / Tree-search model / Instantiated generative model | Simulates prospective state sequences over a planning horizon and infers past states based on transition physics. |
Artificial intelligence
Artificial intelligence (AI): The capability of computational systems to perform tasks typically associated with human intelligence, such as learning, reasoning, problem-solving, perception, and decision-making. “AI” is often used informally as a noun denoting software components with artificial intelligence.
Machine learning: A field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalise to unseen data and thus perform tasks without explicit instructions.
Algorithm: A computational architecture or procedural method that can be trained on data to perform a task. Examples: convolutional neural network, transformer.
Training algorithm: A set of instructions used in machine learning to iteratively adjust the parameters of a model so it can learn from data and make accurate predictions on new data.
Model: A specific, trained AI algorithm. Example: GPT-4o.
Inference engine: A software and/or hardware component that evaluates a trained model on new data and produces output results (e.g., predictions). Example: TensorFlow.
AI application: A system in which one or more critical or high-value functions are realized by an AI component. Examples: ChatGPT, GitHub Copilot, autonomous vehicle
Systems engineering
System: An arrangement of interacting elements that together realize functions. Examples include information systems, biological organisms, ant hills, medical devices, medical laboratories, and space stations.
A system can be decomposed into (sub)systems that in turn can be decomposed into even lower-level systems, components, and ultimately parts. The term can in a specific context refer to systems as-designed (system “blueprints”), systems as-built (constructed, manufactured system), and as-maintained (operational, real-world systems).
System element: System, subsystem, component, or part.
Subsystem: A system that is part of a larger system. This term is only used informally.
Component: A system element that encapsulates a cohesive responsibility, realized by a minimal sufficient set of functions, and that interacts with its environment via a well-specified contract (its provided and required interfaces). If the contract is preserved, the component is substitutable.
Part: The lowest level of system elements for which configuration information is defined.
Risk management
Harm: Physical injury or damage to the health of people, or damage to property or the
environment.
Hazard: Potential source of harm.
Hazardous situation: Circumstance in which people, property, or the environment are
exposed to one or more hazard(s).
Risk: Combination (usually multiplication) of the probability of occurrence of harm and the
severity of that harm. Reduction of risk is the objective of risk management. A risk can be
reduced either by lowering the severity of the harm or the probability of the harm, or both.
The severity depends on the nature of the hazardous situation.
Risk control: Process in which decisions are made and measures implemented by which
risks are reduced to or maintained within specified levels. Risk control measures are also
called risk mitigations.
Fault: Condition or defect in a system which may lead to an error. Synonym: defect, bug.
Error: Manifestation of a fault as an unexpected or unwanted behavior of a system. An error
may lead to a failure.
Failure: Situation in which a system (or part of a system) is not performing its intended
function due to an error. The failure is characterized by its failure mode i.e. the specific
manner in which the failure occurs. A failure is a symptom of an error that may or may or
may not lead to a hazard.
Failure mode: The specific manner or way in which a failure occurs.
Configuration management
Configuration item (CI): A set of functional, performance, and physical characteristics of a system element; a set of true statements about a system element that we choose to manage as a unit. This is the most important term in configuration management.
A configuration item has an extension in time. It comes into existence at one point in time, e.g., when it is defined in the systems engineering process, and it goes out of existence, e.g., when the whole system reaches end of life or when the configuration item is replaced by a new configuration item because of a new system architecture.
Configuration items usually evolve over time as the system is improved (except as-built configuration items, see below). The evolution of the configuration item is documented as a sequence of configuration item versions, each of which defines the configuration information during a defined period of time, the validity period.
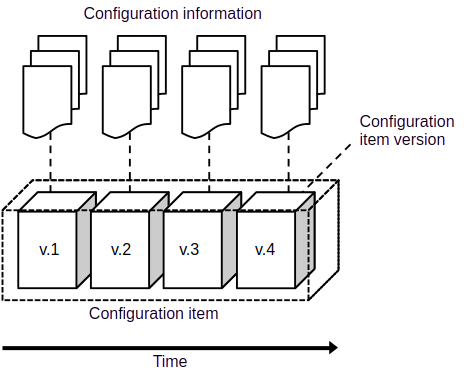
Configuration item versions are in turn documented in the *configuration information*, a set of documents, models etc, associated with the configuration item (see Figure 1a and Figure 3).
In the most general case, configuration management spans over the following types of configuration items:
As-designed configurations item: (Predicted) characteristics of designed (but not necessarily yet constructed) system element.
As-built configurations items: (Actual and predicted) characteristics of constructed (but not yet put in operation) system element.
As-maintained configuration item: (Actual) characteristics of a system element in operations.
A configuration item should be selected so that it is realized by one system or system element. Configuration items should furthermore be selected so that they can be managed with minimal dependency on other configuration items (modularity). Configuration item selection criteria should therefore consider:
- Regulatory requirements
- Criticality in terms of risks and safety
- Anticipation of new technology replacing old
- Interfaces with other configuration items
- Procurement
- Support and service
Examples:
- Components that are procured as a single entity (e.g., an x-ray tube) should be represented by one configuration item that defines the specifications of the component.
- System elements that have their own maintenance schedule and maintenance log should be represented by one configuration item that is all the maintenance-related information.
- System elements that are developed as one entity, with their own specifications, risk analyses etc. should map to one configuration item.
Configuration: A top-level (root) configuration item; the characteristics of a system element that is managed as an independent entity, often a whole system.
Configuration item version (CIV): A (long exposure time) snapshot of a configuration item between two timestamps, `valid_from` and `valid_to`.

If `valid_to` is not set or set to a future date, then the configuration item is currently valid.
For as-designed configuration items valid means released, i.e., formally approved for construction after `valid_from`.
If the last version of an as-designed configuration item has its `valid_to` in the past then it is deleted from the configuration, i.e., the corresponding system element is no longer part of the system.
As built configuration items are kept valid for as long as the system is assumed to be on the market or, in case of medical devices, sometimes indefinitely.
For as-maintained configuration items valid means installed, i.e., operational in a system instance.
An as-maintained configuration item with its `valid_to` in the past is removed from the operational system.
Key configuration item versions (baselines) can also be given a human-readable label, like v2.1.0.
Configuration version: A snapshot of a configuration at a well-defined point in time; a top-level configuration item version.
Configuration baseline: A formally reviewed and approved configuration version that serves as a non-volatile reference point for a well-defined purpose.
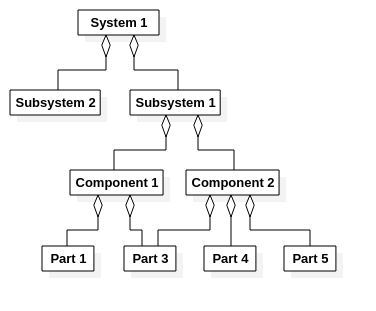
Configuration item graph: A directed acyclic graph (DAG) of configuration items. The graph mirrors the structural decomposition of the system of interest. The reason that the CI graph is not a simple tree is that the same configuration item (e.g., a power outlet) may appear in many branches of the (as-built) configuration item graph in an as-designed configuration. The “acyclic” adjective means that a configuration item can not be part of itself; there can not be any circular part-of associations.
An example of a CI graph is shown in the figure below. Note that Part 3 is part of both Component 1 and Component 2.
Configuration information: A representation of a configuration or a configuration item. Typically a set of documents, source code, models, database records etc that together document the characteristics of a system element (a configuration item).
Information item: A repository of configuration information such as a document, a model, a source code file, or a database record. Information items evolve over time. Their state at a certain point in time is represented by an information item version, a snapshot of the information item at that point in time.
Information item version (IIV): A snapshot of an information item at a well-defined point in time.
Change request: A formal request to change a baseline, e.g., by adding a new function to the system. The change request is not part of the configuration information since it describes a difference between two configuration baselines rather than a configuration baseline.